特征缩放
Mean normalization
为了让梯度下降时候运行速度更快
将$x$的值控制在$(-1,1)$左右

$x_1=\dfrac{x_1-\mu_1}{s_1}$
$\mu_1$ 是 $x_1$ 的平均数
$s_1$ 是 $x_1$ 中最大值-最小值
学习率 $\alpha$
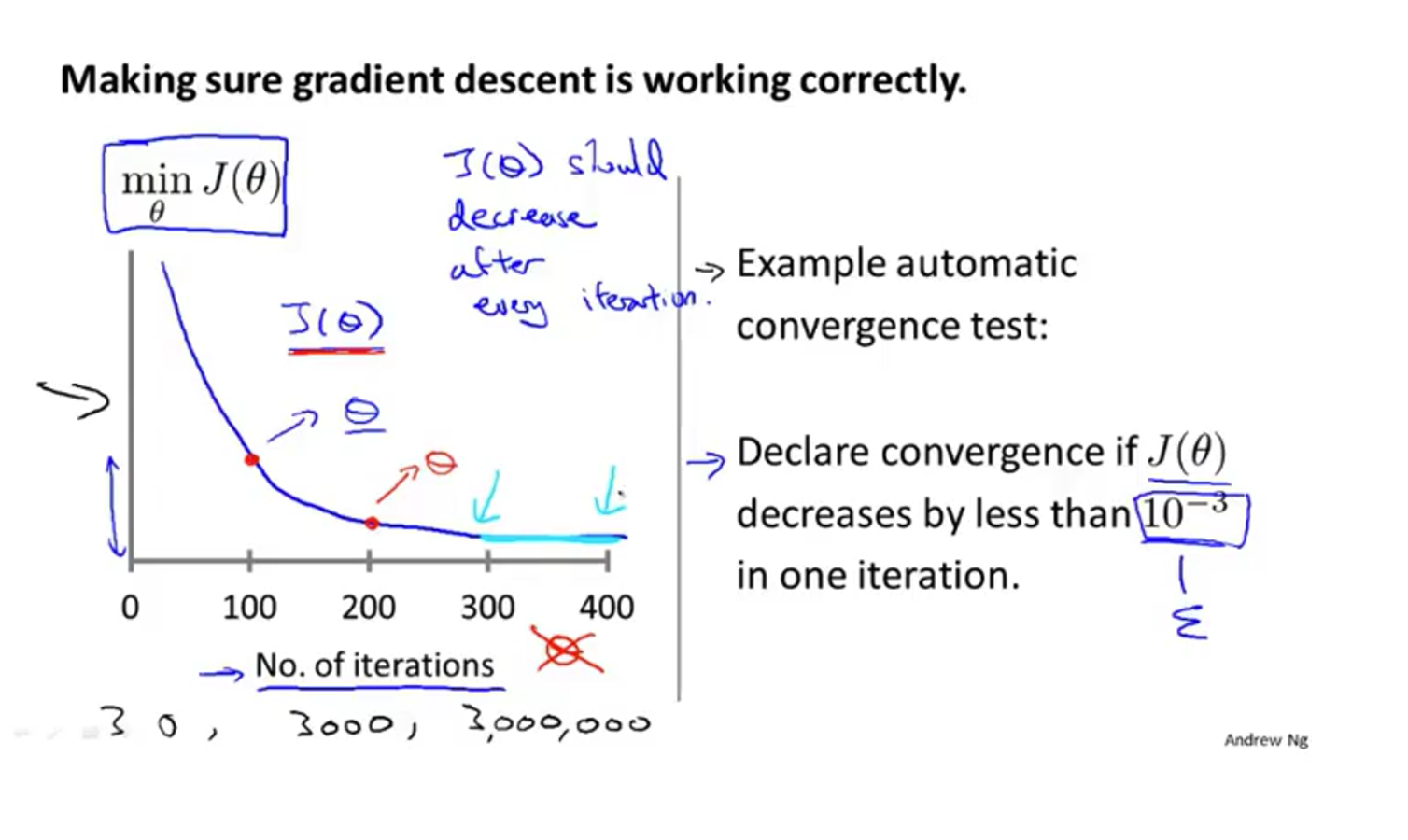
直到$J(\theta)$收敛停止学习
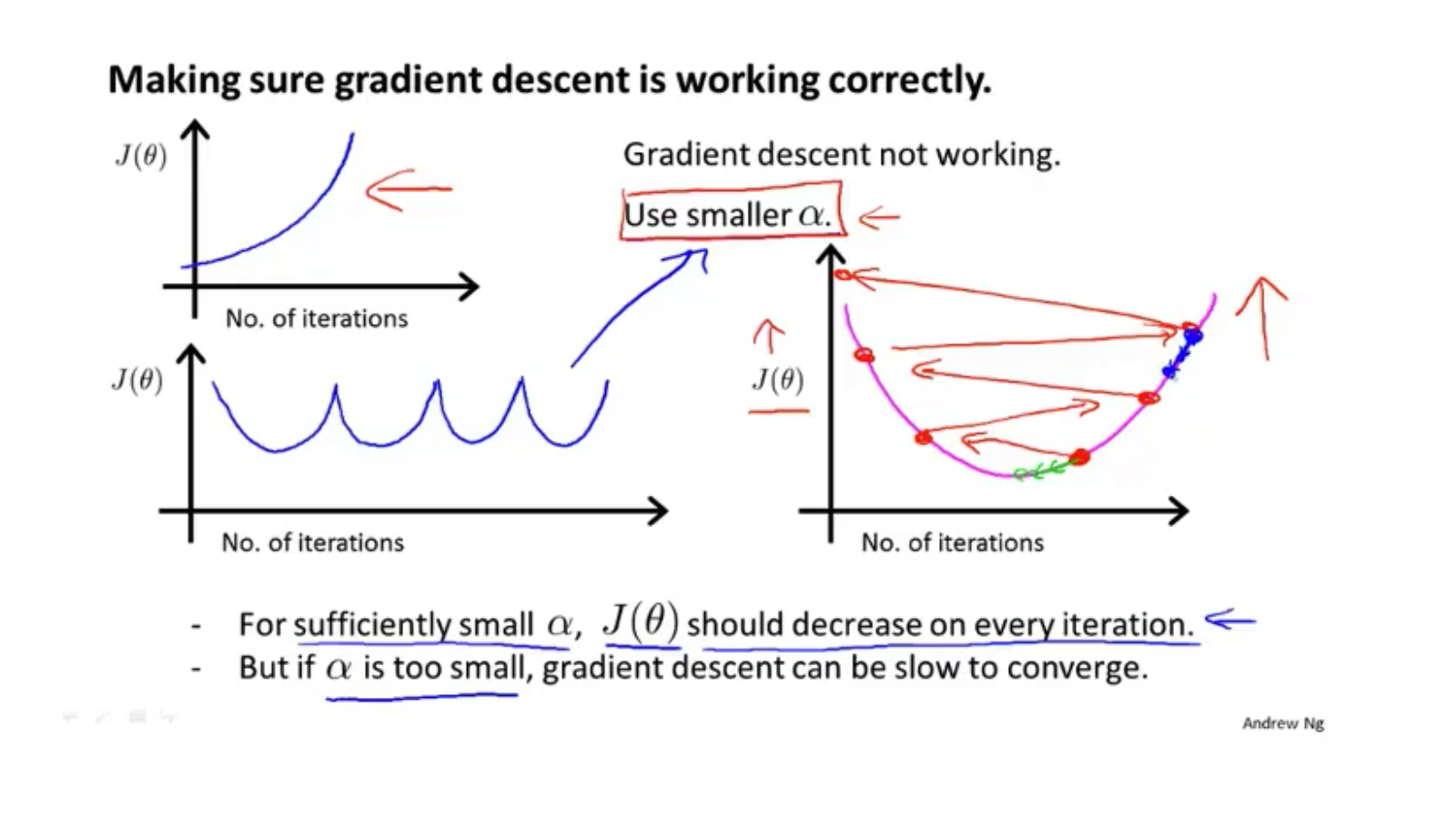
$\alpha$大小应该合适:
太大:可能导致$J(\theta)$变大
太小:收敛过慢
比如0.001,0.003,0.01…
不断尝试
特征和多项式回归
多项式回归 使用多项式去拟合数据
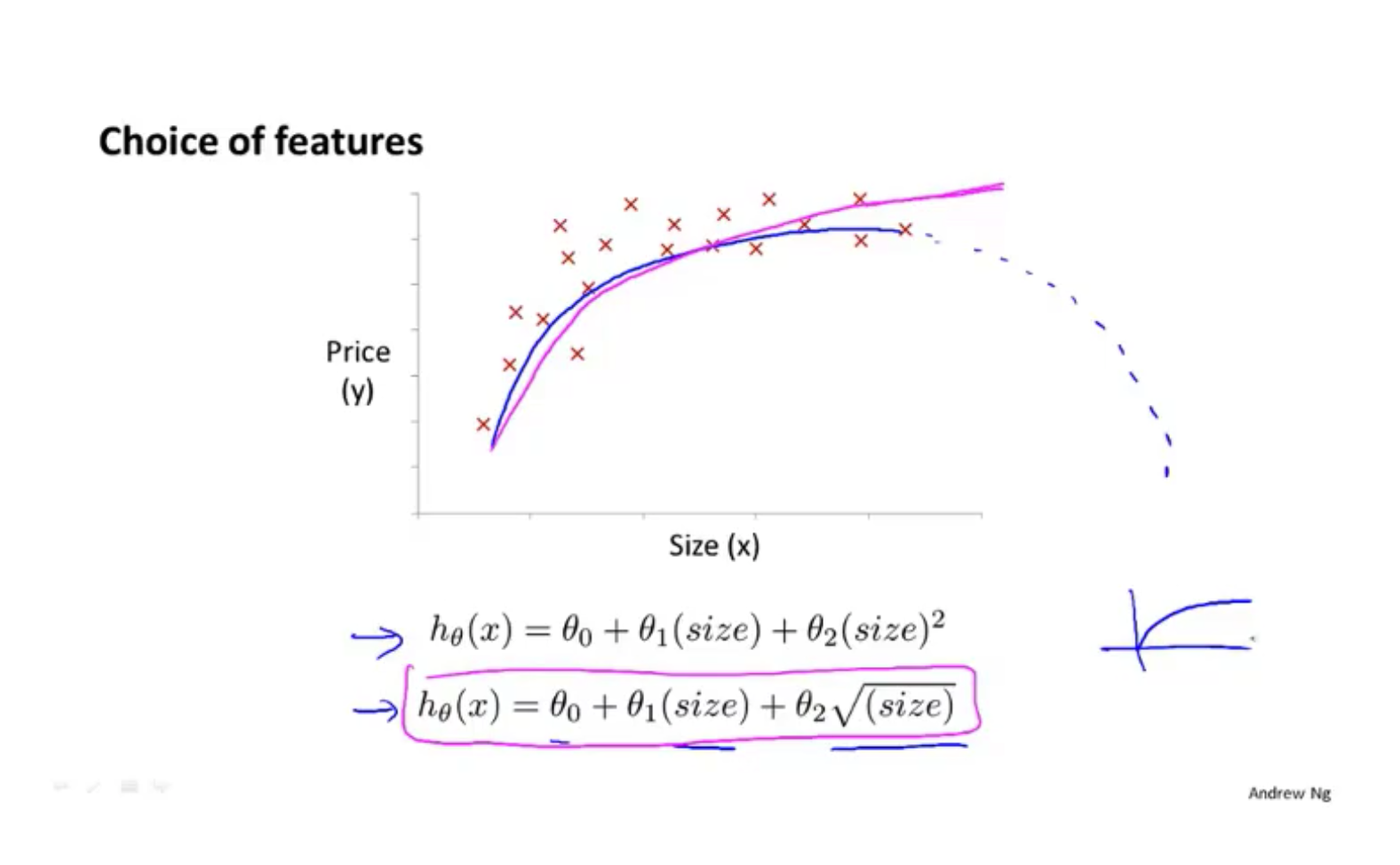
为了不让函数降回来,使用平方根
正规方程 normal equation
区别于梯度下降法,一步到位找到损失函数最小值
比如求导 使导数为0
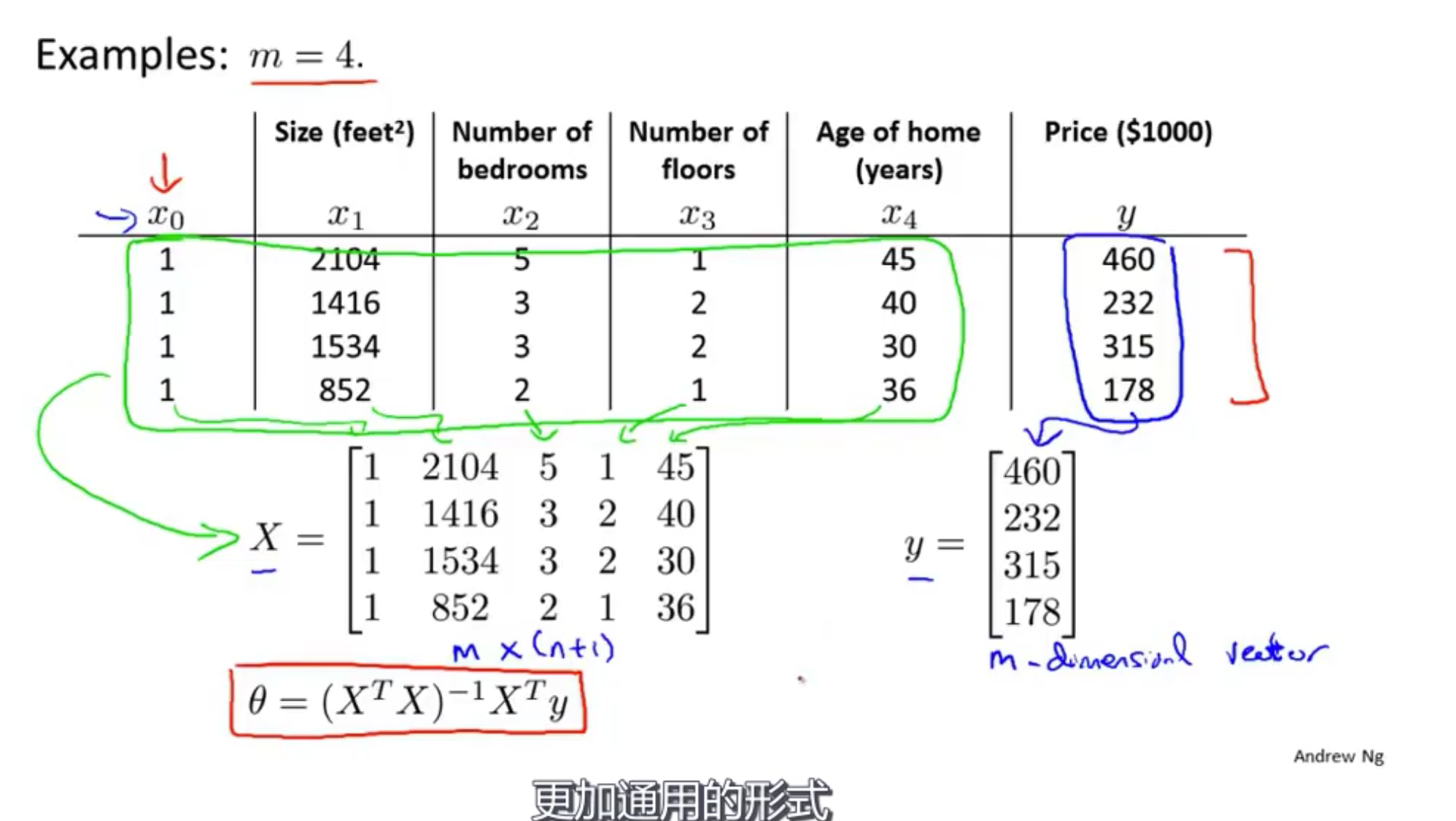
使用 $\theta=(X^TX)^{-1}X^Ty$ 会给出最好的$\theta$值
| 梯度下降 | 正规方程 |
|---|---|
| 需要确定$\alpha$ | 不需要确定$\alpha$ |
| 需要很多次迭代 | 不需要迭代 |
| 在$n$非常大的时候仍旧很好 | 需要计算$(X^TX)^{-1}$ |
| (当$n$大于约10,000使用梯度下降) | 如果$n$特别大就很慢 |
当$X^TX$不可逆
原因:
包含累赘的特征 Redundant features(linearly dependent)
E.g. $x_1=$ size in feet$^2$
$x_2=$ size in m$^2$包含太多特征
E.g. $m \leq n$
解决办法:Delete some features, or use regularization (正则化).
